
Snap! Websites
An Open Source CMS System in C++





 The system process including all the steps I can think of at the moment.
The system process including all the steps I can think of at the moment.
Assuming you give the Snap! server permissions, it blocks IP addresses that misbehave with your firewall. Misbehavior is detected as spam posts, fast hits, or unwanted accesses.
Start the Apache server, check whether it is better (faster) to run Apache and have all special features (redirects and such) in the snap.cgi (i.e. dynamic) or in Apache (i.e. but that last option requires a reload of Apache every now and then!)
See whether we gain anything in having a static cache. The problem with a static cache is that it will not change pages depending on things such as a mobile phone or IE accessing your website.
This one can handle a fast cache. Slower than the static cache if we have many rules to access the cache but still certainly a lot faster than asking the main snap server for advice.
Start the Snap! server which can then connect to the Cassandra proxy server to access all the data.
Because of the way the design works, objects we create in the server have an instance() function. This means all the objects are unique. We may want to look in a way to create a server instance, and all the plugins get loaded once on server start up, but they are included in the running instance (thread) by creating a clone instance and the server keeps a list of those. This means each time plugin A wants to connect to plugin B, A first needs to find the pointer to B, then call the connect function on B. At this time, this makes use of the instance() pointer.
The Snap! server listen for connections on a TCP/IP socket port 4004 by default. This allows for each snapserver to run on a separate computer from the Apache server.
The Ready Cache is a cache created by a backend (a permanently running process on a server that is not answering requests on the Internet) to prepare pages so they load much faster than by having to recreate them on the fly (at least it should be, especially if the page layout is complex.)
The Cassandra Proxy Servers allows our Snap! Servers to quickly and always connect to a Cassandra node. It knows of several Cassandra nodes to connect to in order to maintain high connectivity. (i.e. if a node goes down, then the system know how to continue to run by switching and sending requests to a different node.)
The proxy also removes the need to do retries and other similar issues we can have using a direct connection.
The Backend Processors are similar to the Snap! Servers, only they may run on computers that are not accepting front end connections. This is particularly useful to avoid taking processing time and large amount of memory on computers that are used to directly communicate with clients.
Note that the server and snap_child processes (i.e. the server forks and then runs the connection in the snap_child process) do not make use of threads except in one single case at this point: if it runs a process that require a two way FIFO, the input is handled by the main process and the output is handled by a thread. The is the best way to ensure that the FIFO doesn't block (i.e. input is missing, too much output not read).
Current Implementation. There is still one thread used in the server to handle the STOP and NLOG signals the server may receive via UDP. This thread will be removed once the snapcommunicator is available.
The following figure represents an installation. Each box represents a "physical" computer (these could of course be virtual computers, but if you have your own computers, really, physical computers is probably best since with such an installation and a proper load balancing, you can turn off/disconnect any one computer for maintenance and reconnect it later.)
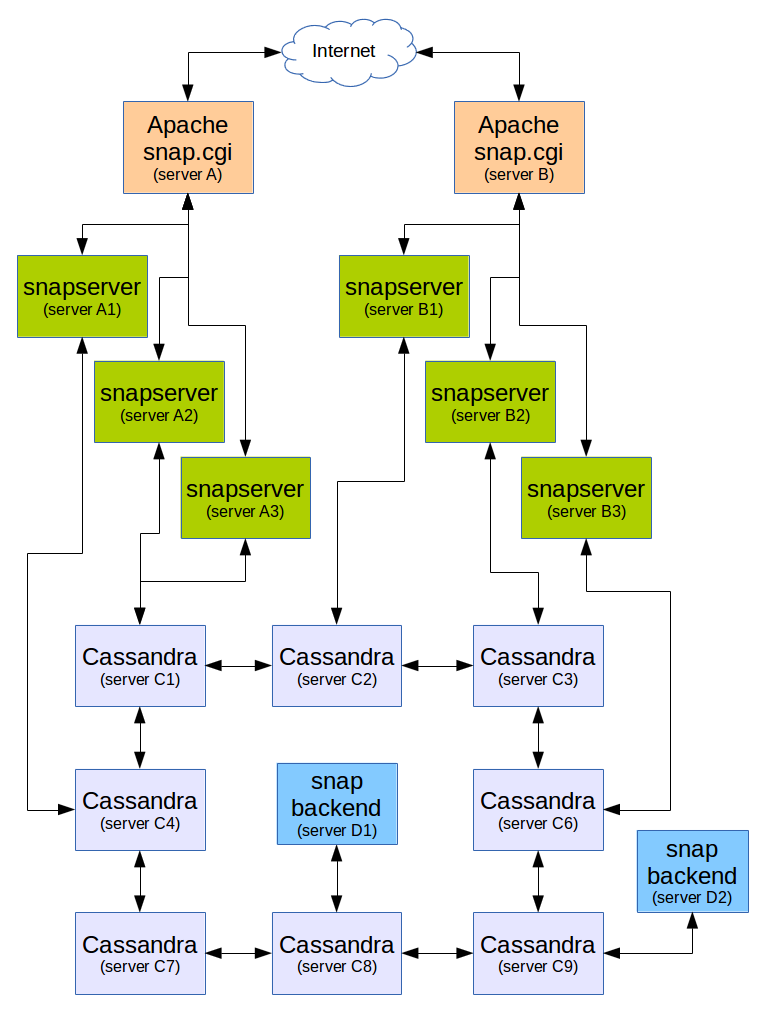
The plugins should probably each have their own page with their own expected processes.
Right now, we consider that two main plugins can be listed here because they are the major processes happening pretty much all the time (i.e. mandatory plugins).
The init() and execute() signals are already part of the path plugin process. The init() requests that all the existing plugins register their name to function entries (using boost signals as the underlaying implementation.)
The execute() matches the path to the name which is then matched to a virtual function. A plugin has to implement that virtual function if it decided to execute a specific path.
However, before calling a function, it will:
(1) see whether the path should generate a redirection1;
We still have a snap_child::page_redirect() function, for module that have to dynamically redirect users (i.e. log in page, once the user is logged in, redirects you to the page you came from.)
(2) check that the current user has proper permissions to access the current page;
See talk about the Permissions feature [core] for details.
There is a verify_permissions() signal which tanslate in two signals:
The verification process terminates with the computation of the intersection of the user set with each one of the plugin sets; if any result is the empty set, then the user does not have permission.
The content (pages) is the main component of a website. It is therefore described here.
[TBD]
Snap! Websites
An Open Source CMS System in C++








