
Snap! Websites
An Open Source CMS System in C++





(Note: I put some references at the bottom--links to other pages that are related to this.)
At this point, we have made progress in the conceptual (At least) implementation. Note that the libQtCassandra already works and the support of the tables as described below is possible and has already been used in a few places.
The thinking, however, somewhat changed. We want to implement the tables in a way that is very agnostic to the plugins in order to make sure that we can always change the backend if need be (one day we may want to offer support of other databases, even possibly MySQL or PostgreSQL, although we really don't have any such plan at this time.)
Every plugin is given access to the database via a very minimalistic API: a "database" object which supports functions to load and save parameters that are managed by the plugin. The API allows you to select a context and allows you to enter name / value pairs. The database object is made specific to each plugin so that way objects that are specific to that plugin can be saved in a table using keys that are specific to that plugin and in case of an extension to an existing table (i.e. the page table...) the field names will be prepended with the name of the plugin. For example, the language plugin would have fields named "language_<some name>", however the programmer of the language plugin doesn't need to know that this is happening.
The context determines where the data is to be saved. It may be specific to the current page (i.e. the language of the page,) the current user (i.e. the real name of the user,) the current session (i.e. attached to a cookie,) a global variable (i.e. shared between all the users, pages, sessions,) etc.
The interface available to the plugins is therefore completely agnostic in regard to how the data gets saved in the database (although that may complicate the handling of indices, TBD.)
class db_interface { public: void set_context(const QString& context); QByteArray get(const QString& key); QByteArray get(const QString& context, const QString& key); void set(const QString& key, const QByteArray& data); void set(const QString& context, const QString& key, const QByteArray& data); };
The set_context() can be used to define the context and thus avoid switching all the time. The default will be the current page. We also offer a get and set that define the context on the fly which is useful to go get a value. We may also offer a set of core get/set that use core contexts defined as enumeration numbers (much faster than managing a string.)
Note that all those fields are considered data and thus their column names all start with data_...
For now plugins have direct access to the Cassandra database via the snap_child object. We may want to implement the interface there, but right now it seems somewhat premature. Also the snap_chlid as well as some other objects (sanp_server, content) have functions one can use to access different data available within those objects.
All the objects are the same in our environment, giving us a single base object that supports all the possible data that you want to add to the system.
The concept is pretty simple and will be developed over time, although we would like to be able to create C++ objects too, and that may require many interfaces because the plugins cannot directly derive from a lesser level class since the core will create the object and when doing so it cannot know which plugin should create the object instead so it supports all the possible features assigned to that object. On the other hand, if two plugins add parameters to the same object, how would we create a corresponding C++ class? (it would need to derive from multiple classes at run time!)
The main organization will require a picture, but there is the main concept:
The root node is called Types as it defines all the types used in the system. Everything is typed one way or another (one main type of which you are a child, and any other type defining details about your object: for example, a page can be assigned an author.)
In order to segregate the content written by users, we offer content types. For example:
Of course, a Page could be further segregated in several content types and further on any number of levels. Say for example you are creating a book about all sorts of insects, you create sub-types under Page categorizing insects (maybe with a type "not an insect but often viewed as such" to list animals such as spiders.) The categorization of animals can go several levels and this typing can start right here.
Whenever someone creates a page we get something like this:
Types -> Content Types -> Page -> (user created page)
Defines the set of users who have an account on this website.
Under the Users type, we have the actual users. Grouping of users is done using groups (see below.)
The administrator user could be given these parents:
Types -> Users -> Administrator
If creating many different websites and putting all the users for one website just and only under that one website, then each user will have to register a new account for each website in order the manage them, post comments, etc.
A better idea, although a log in is still required to use a specific website, is to create a system wide user table. This could also be viewed as a concern, but there shouldn't be anything special about this since the permissions / rights that one has on a specific website are specific to that website. If no permissions appears, then the user may not even be allowed to log in.
Assuming our system is capable of such a feat, the user should be able to change (edit) his user data from any one website. This just requires the user form(s) to be shown whatever the site.
In order for the same log in information (cookie) to walk along the user we would need to use an IFRAME. Facebook does it that way (i.e. the Like button may show your icon, that's because it uses an IFRAME which can send the cookie information to Facebook. Same thing with the Page Widget.)
On our end, the IFRAME would point to our https://snapwebsites.com/ system (which happens to already include the user log in information when they register for an account!) The normal log in screen could make use of the IFRAME with either the log in form in the IFRAME or the SUBMIT button to send the data via the IFRAME instead of directly to the current website...
TBD -- we have to think about security in that regard though!
The action taken by users are defined by the action types. This is important for permissions are linked to actions. For example, the Edit Menu permission is linked to the Update action.
At this time I can think of the following actions but that is very likely going to grow:
We will have to be very careful not to add permissions in the list of actions and vice versa.
The actions are defined as follow. They are used when checking permissions.
Types -> Actions -> View
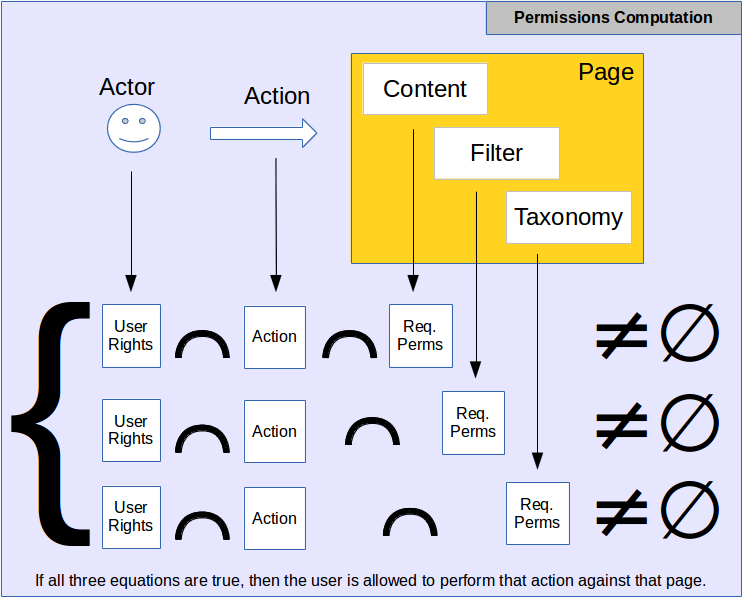
The permissions allows users to apply or not apply actions on objects on a Snap! website.
Actions were defined just before. Permissions are lists of objects and what actions they accept. "objects" are generally defined as a plugin although one plugin may support multiple "objects" and vice versa, multiple plugins may represent one "object."
The permissions are added as required by end users and plugins.
The core supports quite a few permissions allowing it to control all of the basics of Snap! websites, but it is very easy to add more permissions (i.e. the scheme is such that plugins don't need to compute the permissions themselves, only to check whether something is legal or not permission wise.)
The last entry: View Content should be assigned to all the users, but especially the anonymous user (there are websites which hide data to logged in users, data that is otherwise visible to anonymous users—for example, the home page of Facebook allows you to register an account; once registered it shows you your wall instead.)
We will add permissions as we need them. There is a detailed talk about permissions here: Permissions: Union / Intersection operators. The implementation is very straight forward:
The plugin check includes the action information as well. The permission sets are built depending on what the user tries to do, i.e. the action (view, create, clone, edit, moderate, archive, delete, ...)
Food for Thought
The main types should be locked: the root Types data, the top-level types such as Content Types, Users, Permissions, etc. and probably some second level types such as the basic actions and permissions (i.e. the permission used to lock those nodes cannot be deleted and thus needs to be locked, so it has to actually lock itself!)
The lock must at least prevent any user from deleting that data without a way to unlock this data. It is also likely to prevent them from editing the data. This can be done by creating a permission that somehow cannot be assigned to a user. The editing of data at all levels is permitted (but not deletion.) This is important to allow the user to do things such as define the layout of his website (set the layout on Content Types,) or to set the layout to a given type of pages (set the layout on Page or Story.) Similarly, all sorts of data can be defined at any one level. It should also be easy to put a set of types inside a group and define some data on that group instead of each individual type. This being said, I'm not too sure how we can deal with that one (i.e. can the same data type be defined in multiple groups, and if so, which one has priority for the Layout, which one has priority for permissions, which one has priority for this or that...)
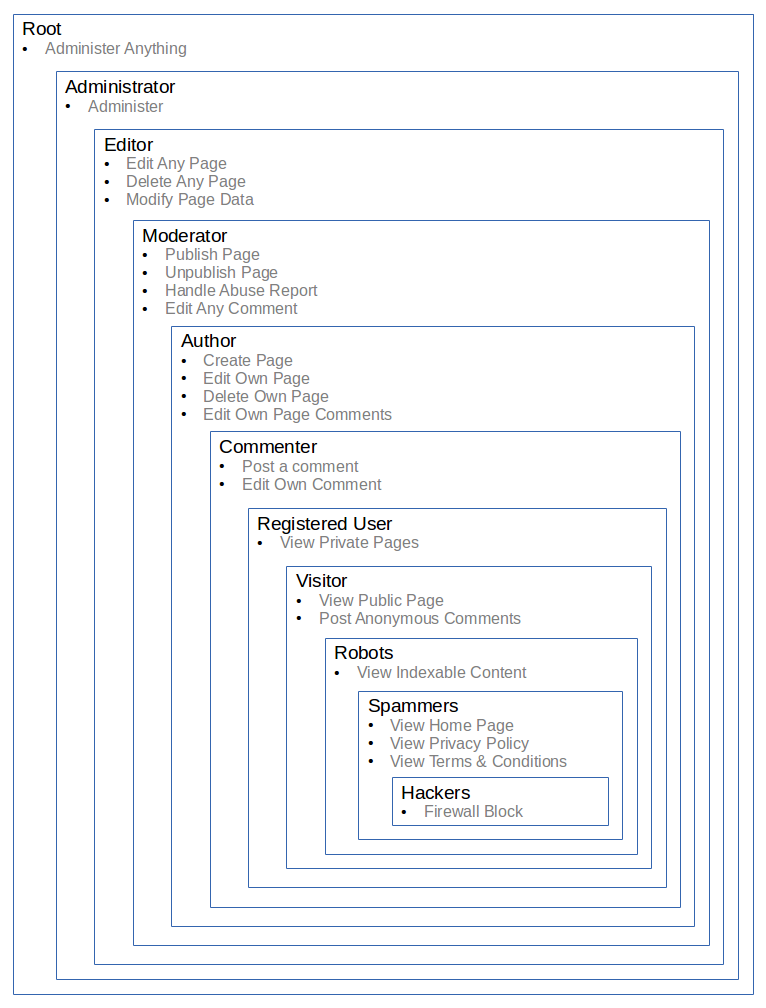
Users can be assigned to a group (also content, etc. since we can always link those with groups.) This gives them all the permissions assigned to that group (i.e. it is cummulative, the function is a union.)
For example, the Anonymous Group could be assigned the View Content and Create Comment permissions. Any user who is assigned the Anonymous Group will be able to view content and comment on it without us having to assign those specific permissions to each user.
As with other objects, the groups can be defined in a tree. If you are assigned a higher level group in a tree, you are given all the permissions defined under that tree. On the other hand, if you are given a lower level group in the tree, you only have those permissions defined in that lower level group.
Example:
Types -> Groups -> Anonymous (View Content, Create Comment)
Many things are to be linked between each others (in the object declarations shown before, the tree is formed of nodes that are all linked parent/child and siblings with next/previous links.) For example, the definition of a user is tagged as such with a link to the User term. All the links are to be saved with the data as columns starting with the work link_...
To support the links we most certainly want to include get_link() and set_link() functions in the db interface. These would work the same way as the other data, except that the introducer is set to link_... instead of data_...
Most contexts will accept links. We may have to create links both ways (i.e. link_... to go from A to B and back_... to go from B to A.) This way, we can find that a user is part of the group named "Registered Users" and vice versa, we can find all the users who are part of the "Registered Users" group.
Note: we will need to be able to quickly search who is link and how. So this needs to be thought of a little more before implementation.

The figure shows a basic organization for one page called Home Page.
The Home Page is assigned the View Content, John as the author, Home as a tag from the Index taxonomy.
The user named John is an administrator.
The View Content is for View actions, the Edit Any Content is for Update actions.
Many things are missing in this graph, but it gives a good idea of all the data nodes and their linkage in order for the system to work.
I started writing this page thinking that the base of everything should be called Page. I'll change it later, but now it should be Content instead. We will have two modules: one Content plugin that manages the base tables and allows ALL the other plugins to offer pages to the users (administrative or not); and one Page plugin letting users create "HTML pages" with their chosen layout and content.
So, the Content plugin offers a certain number of basic Content Types such as the administrative pages. By doing so in this order, we can much better organize the entire system to make use of ONE content environment that has its one specific permissions, URL handling, etc.
In order to initialize the tree we want to offer the user a way to easily write a tree in XML. The system can then load the XML and transform the data in a valid Snap tree in its Cassandra database.
The following is a preliminary definition of the XML schema:
<snap-tree>
<content path="...">
<param name="..." overwrite="yes|no" force-namespace="yes|no">...param value...</param>
<link name="..." to="...">...destination path...</link>
</content>
</snap-tree>
The files are added using the content plugin add_content() function. Once all the content was added, an signal is triggered for the content to be sent to the database. At that time the content plugin can sort everything out as expected and save the data in the right order (mainly, whenever a link is required it needs to save A before B if B links to A.)
When a file is submitted with parameters that already exist in the database, they are generally not overwritten for the current value is in general what's expected in the current system. The overwrite attribute can be set to "yes" to overwrite the data each time (it defaults to "no").
The parameter names are expected to be for that specific plugin, which means that their name is changed with <plugin-name>::<param-name> to properly qualify each parameter. At times, a plugin may be adding a parameter for another. In that case, the parameter name will already be fully qualified and to avoid having the system add the plugin namespace, set the force-namespace attribute to "no" (it defaults to yes.)
Plan of action (steps to achieve our goal)
| Attachment | Size |
|---|---|
| content-organization.odg | 14.44 KB |
Snap! Websites
An Open Source CMS System in C++








