
Snap! Websites
An Open Source CMS System in C++





At this time we're testing Cassandra to properly understand how it works and make sure we can use it the way we're thinking we want to use it. This works. See libQtCassandra
Next we want to implement a simple test to check cTemplate and see that we can (1) create a simple layout with variables and fill in the fields; (2) extract the fields to generate the dependencies. We changed our plans on this one we'll be using XML and XSLT to transform the XML to whatever output the user is interested in (HTML, PDF, Text, RDF, etc.)
As we're working with Cassandra, make sure we can get it to talk to another node via an SSH tunnel.
Start getting a basic app. that take a page data from Cassandra and generates the output with the layout selected for that page and cTemplate. This works for files for which the output is not XML. For example, robots.txt feature works. We also have a XML Sitemap feature (which is XML but not in the sense meant by the standard HTML or XHTML output.)
Once this works well, we have a "static" (non-editable) website capability that we can test through a browser so we want to implement the two layers of our application: very small snap.cgi which connects to the snapwebsites server. The server needs to be able to return the compiled page(s) to the CGI. We have that already. The snap.cgi and Snap website server are communicating as expected and the server is already capable of sending data back to Apache including real HTML pages, CSS, JavaScript, images. The Editor feature [core] is even capable of saving inline images as Attachment feature [core] and returning them through an <img src="..."/> tag.
At this point we want to implement the necessary elements to generate the HTML output of a page of content. This requires many elements and thus requires a little bit of thinking. See Content Object in Cassandra (Content Tree) for all sorts of details. This works already although we are looking into including branchs, revisions, and secret data support early on because we are actually thinking that it will be easier to implement now rather than later.
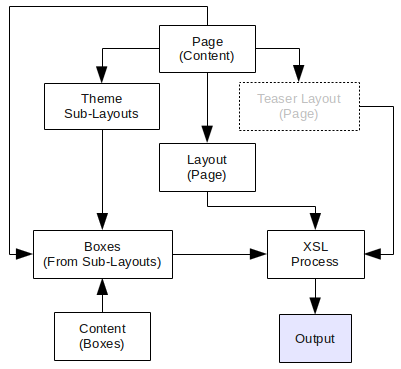
This presents a simplified view of the handling of a
Page to it's Output.
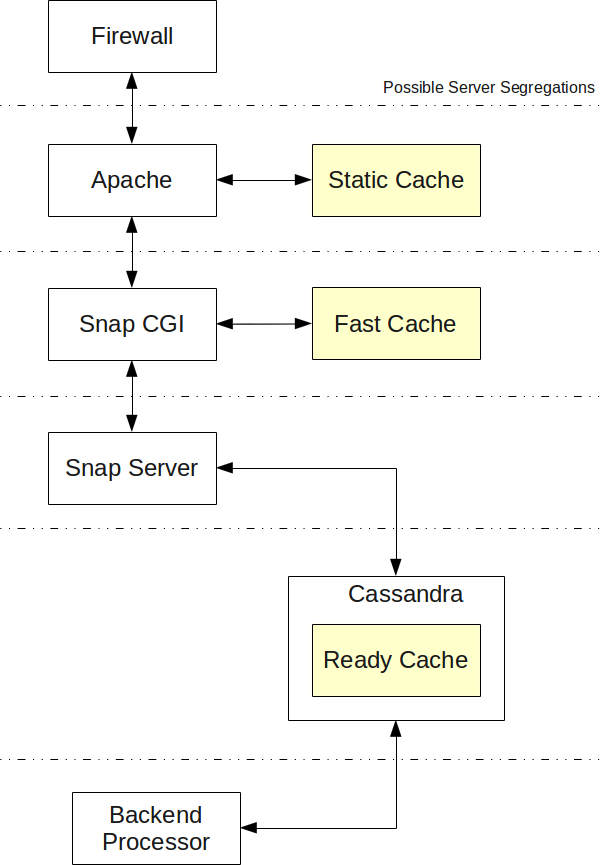
The following shows how the data flows from the Internet to Snap! and back out. The Snap! server and Cassandra can each be on different computers than Apache, although at this time we plan to have the Snap CGI talk to the Snap! server via a Unix socket to make it as fast as possible (this is implemented and working with a full TCP/IP socket.)
Note: our first Snap! C++ version will not include external caches to simplify our implementation. (i.e. the only cache is Cassandra's memory cache at this point.)
Snap! Websites
An Open Source CMS System in C++








