




The website must be capable of supporting users. For this purpose we'll use the content type "users". Users are defined in that content type and therefore benefit from all the capabilities offered by the content type (revisions, signatures, pictures, extra fields to enhance the default profile of a user with things like an address, phone number, etc.)
There are two main categories of users: anonymous users and registered users.
Registered users are viewed as anonymous users until logged in, although we can make use of several level/degree sessions and know that someone is returning even if not logged in (i.e. long term cookie but short term session.) This way the website can react by showing a site somewhat different to a returning user (i.e. hide the big huge red button saying: Please Register Now! and replace it with a Please Log In! button.)
Speaking of that, we should try to technically get a secure and a non-secure set of cookies so we can detect people who get back on our site on a non-secure page. If I'm correct the idea would be to send a secure cookie and a non-secure cookie when on HTTPS. Is that possible? Only accept the secure cookie when doing important things (edit account info, cart, etc.)
The user sessions are used for a certain number of things: know whether the user is logged in, adding items in a cart, keep track of search queries that the user has done (i.e. and offer that as a default on a next visit.) The list is endless. However, there are two important points with sessions:
Both of these points are solved by us by using ONE cookie that is 100% handled by the core system (or 2 cookies if we can have one secure and one non-secure.) This will be a lot more secure and a lot more likely to work every time. The only thing that may happen is that some AJAX wants to keep a few local variables. In that case, they should use a library such as jQuery to handle their own cookie (permanent) variable. If possible, these should be marked as local to the browser (i.e. should not be sent to the server so as to avoid leaks whenever the connection to the website is not protected by SSL and make transfers smaller.)
The log in form must be protected against brute force attempts to log in. This means to block accounts whenever the user tried to log in without success. Like Yahoo! we can also add a CAPTCHA on the 3rd attempt. To unblock, get an email sent to your registered email.
Passwords should be handled so they are long enough, hard enough to guess, need to be changed every 90 days, etc. See below for an extended talk about passwords.
Sessions should auto-log out users quickly by default (i.e. 1h instead of 3 days!) Also, we may want to have a flag "Keep me Logged In". Still, that requires a 2 level log in scheme, if you want to change something important to your account or make a purchase, you still need to log in anew.
Repetitive log in attempts from the same IP address can also be viewed as bad, especially if each time a different username is used.
We should also give the option to a user to setup an account to only accept log in from a specific IP address. That way, you give yourself (the top admin) the right to log in only from home. You can always have another user who doesn't have as many rights to log in from anywhere on the Internet.
Although we cannot be sure of the same security level from other systems, we should offer users to log in via Facebook, Twitter, Google+, etc. all the OpenID available. It would be good if they could all offer an OpenID mechanism instead of each have their own API... oh well!
By default, Snap! Websites offers users to register with a website by going to the Register form.
Note: The current version does not yet distinguish registrations between different websites.
The registration process forces the user to verify his email address. This includes sending an email with a link and a code that can be used to verify the account. Once verified, the user can log in normally.
The log in process requires a password. If the user forget his password, we offer the user to make use of a form to request a new password. This form asks the user his email address. If the user is properly registered, then he's sent an email with a link and a code that are to be used to change their password. This process makes use of a special session that allows the user to access that form, but prevents him from using it if he did not ask for a new password. This is important as this form only asks for the new password and not the old one.
The following figure presents the existing registration and log in process without all the error messages. Several different types of anti-hackers mechanisms are to be added as well.

The following are points that are the things still to be done to complete the registration and log in process:
I was looking for a problem or another and found a post on StackOverflow.com that I found interesting about user login in.
An interesting concept is to make use of the DELETE method to log out with a path such as /user/123/logout and that should be a valid page (where we let the user know that he was logged out.) But the most important parts are:
1) Always create a separate /login page (i.e. a AJAX only login is not clean, the form should clearly come from another page)
2) Send the result to yet another page (and not back to /login)
3) Use the DELETE as the log out method
In Snap! C++ you can create many websites, although many users may only create one site (that's already a lot of work if you do it well!) When you have to manage many websites, it can be quite practical to have one single account for all of them. Although changing your password regularly is certainly even more important, it would be a nightmare if you had to do so on 100 websites, one by one, wouldn't it?
So Snap! creates users that are global in the Snap! environment. That means one account, one set of settings, one log in / email / password for the entire system.
Global usre accounts are created using the users table. Each row is an email address representing the user (i.e. "alexis@example.com".) That row includes all the settings of that user.
To strengthen the security, we also offer an extension where users can be asked a username instead of just an email address. This adds in security because it is generally harder for hackers to find out someone's username opposed to their email address which is most certainly a public matter! The username is kept secret except to the user itself and top level administrators. Note that this security scheme is fairly limited since each user must have a unique username and thus when registering you may find out that a given username is already in use and thus can be used to log in some websites.
The username capability makes use of a row as an index named "*username*". This way we can immediately find the email address associated with a given username.
There is a problem with deleting anything in any database system. A page is a problem because then search engines cannot find the page anymore. This can cause ranking problems. A better solution is generally to redirect people.
However, when deleting a user, you generate a different kind of problem: all of a sudden any data that was generated by that user is not assigned to anyone. There are two main solutions to this problem:
1) Users cannot be deleted, only blocked and hidden. This is good because then anything that this user created remains linked to him/her.
2) Users are deleted and all their data is attached to the anonymous or "nobody" user ("nobody" is better if you consider that some data may be editable by anonymous users.) This can be viewed as okay, however you lose some information in the process.
Note that this applies to all the linked data. Instead of deleting, anything that is linked to anything should probably just be marked as "hidden" or "not available" or "obsolete."
Most users can be deleted, however, some it should not be possible to delete certain accounts. For example, the root, administrators, anonymous, authenticated users should always be kept (although either one except root could be temporarily blocked and/or hidden.)
Most sites will accept a password from you and you never have to change it ever (i.e. Facebook.) However, some websites, especially banks and similar financial institution, will ask you to change your password once every 3 to 6 months.
Our system needs to support many different features similar to this one.
We want an automated system that makes password time out after a given amount of time specified in days or a certain number of usage counted on a per log in successful attempts. This can be turned off, and it can be used depending on the level the user wants to use or has access to. (i.e. A user who cannot access level 2 pages probably doesn't need to change his password because his account is safe.)
Implementation: Password Timeout
We want to check the strength of a password when the user creates a new account or when the user changes his password. The strength is checked using JavaScript first so we avoid a server hit for nothing. Then we check on the server since hackers can bypass the JavaScript check.
Note that this is a good feature to also avoid a certain number of robots to auto-register on a website.
A strength check includes:
Implementation: Minimum Length, Minimum number of letters/digits/... (6 different types of characters), Dictionary check (password blacklist)
Passwords are saved encrypted using a one way encryption scheme. We do not want an encryption that can be used to decrypt our user's passwords.
We want to offer administrators a way to choose the encryption mechanism. Especially, we want to make use of bcrypt by default instead of SHA512.
Implementation: SHA512
For higher security, when a user is asked to change their password, they are asked to enter a new password. Any old password is kept in the database and checked against so new passwords can clearly be a new password (i.e. if you new password match any one of the X old [previous] passwords, then the "new" password is refused.)
The old passwords can be made to time out after a while. It can be viewed as a security issue to keep too many passwords in one's database, although Snap! lets you do that if you'd like. The repeat is checked against a minimum number of old passwords and a period of time. Both are viewed as a minimum so you may keep the last 5 passwords for a very long time if the user is not forced to change his password on a specific schedule.
Also, Snap! has a way to prevent changing one's password back to back. Although our way of handling old passwords will already in itself the change of a password to return to your old password (i.e. change the password 5 times, then on the 6th, re-enter your current, now new password... that will not work with Snap! even with fast password changing requests not turned off.)
Implementation: Prevent Reuse of Old Password, Prevent Back to Back Password Changing
As part of the password repeat, we should check for password similarities. Unfortunately, since we use password encryption, similarities cannot be detected.
However, we prevent password that are too similar to the user name or email address.
Implementation: code available, not tested nor in place for use yet.
By default browser will allow users to save their password on disk. This is generally considered okay for most websites. However, websites that have payment facilities (e-Commerce, Banking, Insurance) and similar, generally require browsers to not save passwords.
Since we are using the contenteditable attribute on a div to allow users to enter their password, browsers are not likely to save that kind of data (they seem to only save fields in standard HTML forms). We still want to offer a way to turn off the auto-completion scheme, in case the browsers behavior starts changing.
See: Security Considerations (Auto-Completion Off)
As users attempt to log in their account we want to count the number of successful and failed attempts. Over a certain number of failed attempts we want to block the account. Later, when over a set number of additional attempts, we want to block the IP address.
A successful attempt may reset the failures completely, or only partially. So the next time the user logs in, if many mistakes take place again, we may actually question his identity.
Also, if a user with the same IP address attempts to log in using different log in names and each time getting an invalid password, that user must be banned quickly. One user should not have much more than one account, and even if he has more, he's not likely going to switch between accounts that fast. If he's trying to get in A, why would he try to log in B without first successfully getting in A?
Implementation: Block account after too many failures, Block IP address with firewall after too many attempts once the account is blocked
By default we want sessions to last a short period of time such as 1 hour. This can be changed in the settings, but that's an important default, especially if your website supports a cart (i.e. e-Commerce features require a short lived session.)
For that purpose, we may want to have a two level logging system:
Level 1 — you are logged in for a long period of time (3 days, 1 week...) and can do many things (post new pages, edit pages, etc.)
This type of session has a time limit that is extended each time the user hits the website. In other words, if your long session is 3 days, users on come on the website nearly every day will rarely have to log back end.
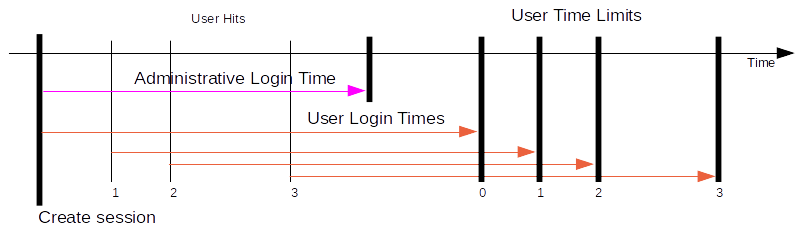
Level 2 — you are logged in for 1 hour at most and can do everything that your account allows you to do including checking out with a payment, deleting content, managing the website. This type of session does not get extended. If your website is setup to give you 1h, then after 1h the session ends and you cannot access these pages that require a higher log in level.

There are several problems linked with an automated log out feature. At the time you're being logged out, you may be doing something that requires you to be at level 2. In that case, we should always be able to ask the user his password via a pop-up and Ajax. That way we don't have to save a form temporarily or some other complex settings of the current page.
However, assuming that the user has to be timed out, a form can request to have an auto-save feature and the data will be saved and the user logged out at that time. The auto-save may also work after 5 minutes, when the time out happens 10 minutes after the last user activity. Note that we must somehow know that the auto-save is just that and not the user accessing the site (i.e. the timeout delay must not be changed when the auto-save feature accesses the server.)
The other big problem is that the current page may need to be deleted from the browser. This is particularly important if the page includes information that is considered secret. The pop-up can visually hide the content with the use of a black background covering the page, but that doesn't get rid of the page from your browser. The content in the browser needs to be removed by going to a different page at some point. So that pop-up + Ajax is a neat idea but in cases where really important data could be at risk (i.e. a credit card number in a form,) we need to clearly wipe out the content. For this purpose, we certainly want to create another level:
Level 3 — your logging mechanism is like Level 2 (i.e. logged in for 1 hour) but the specific page has a much shorter time out (i.e. 10 minutes) after which you are automatically redirected if you did not submit the form.
So... if the logging module redirects you, a usual procedure is to redirect the user back where he was so he can continue what he was doing. This works in many cases, however, we have to offer other plug-ins a way to prevent the redirect or use their own redirect. This is important because the redirect may not be possible without, for example, first entering a secret code on another page. In case of a cart checkout, you may have a final page before actually processing the request, page that presents to your users the full content of their cart. When relogging in, the user should probably be sent to the checkout page just before that.
To make the auto-log out effective, it needs to work on both: the client and the server. The server doesn't need to have a timer. Instead, it can check the duration between the last hit from the user and the current hit. If the elapsed time is greater than the session allowed, then we consider the session as timed out.
The client, on the other hand, needs to have a timer. There are two ways to setup a timer on the client's machine: a refresh meta tag (no JavaScript necessary) and a JavaScript timer. We should always install both and if the JavaScript kicks in, remove the meta tag. The problem of the meta tag is that it cannot open a nice Ajax pop-up to request log in information to keep you logged in. However, it is a minimum to handle level 2 and 3. Level 1 timeout is certainly not necessary on the client side.
Implementation: We have some level of auto-logout available.
We want static URLs, which means that the URL does not change depending on the user using it, giving us a way to write documentation with static links to pages of interest.
Let's assume that we define the current user profile under /profile.
The current user can edit his settings using the path /profile/settings, /profile/password, /profile/avatar, etc.
In different circumstances, we want to be able to view another user's profile. In that case, the identifier of the user must appear somewhere.
Unfortunately, this doesn't play well with static URLs. (i.e. we need a fork)
At this time, there are a few solutions I can see:
1) A la Facebook: use a query string
Facebook actually does it the other way around, /username/?sk=function
(it certainly makes sense as their website is all about users.)
But using /profile/settings?username=someone would work for us
Problem is, ?something is not search engines friendly.
2) A la Drupal: use another path integrating the user name
Drupal uses /user/username/function
Actually Drupal has a me module which supports /user/me/function for the current user.
3) A la Unix: make use of the tilde character (may clash with Apache)
Unix uses ~username/function
This is essentially the same as Drupal, just /user/ shorten to ~
Unix has a current user syntax which is ~/function
4) A la blogspot: use a sub-domain for the username (means a heavy DNS!)
In other words, use a URL such as: username.example.com/function
This uses a lot of resources in the DNS system (FYI: BIND is usually not so good when you need to handle thousands of names--it becomes very memory hungry.)
This syntax can easily support a me capability as well: me.example.com/function.
We may want to use the static URLs as dynamic redirects to the full URL that includes the user name. So when a user is sent to /profile/settings, the URL is changed using his name: /profile/username/settings.
Implementation: We already support a /user/me
The problem I'm talking about is what's called a fork.
A case where you have 2 (or more) choices and thus it cannot appear in one single flat URL (not without some form of duplication.)
Using a mechanism similar to the Drupal scheme and add a dynamic redirect on /profile/function would most certainly make the most sense. The /profile can then be banned from search engines using the robots.txt file.
At this point the user registration, user email validation, making a user a root user, and forgotten passwords are all working. We are still missing the user profile viewing and edit. Also the handling of private and public profiles.
I have put some "Implementation: ..." comments in the rest of the document to show various parts that are now implemented.
| Attachment | Size |
|---|---|
| Registration-Login-Process.odg | 25.69 KB |
Snap! Websites
An Open Source CMS System in C++









